
Essa vai ser a documentação oficial do meu projeto de estudos focando em infraestrutura, mais especificamente, dominar o Nginx.
Recentemente, dando uma olhada no mercado, vi várias vagas pedindo conhecimentos em Apache e Nginx. O Apache nem tanto hoje em dia, mas o Nginx está em todo lugar. Em 2024, eu já tinha tentado usar o Nginx em uma aplicação minha e falhei miseravelmente. Não entendia o conceito e não consegui implementar direito. Mas agora o jogo virou.
Se a gente for simplificar, esses caras são os "recepcionistas" das requisições web. Eles ficam na porta de entrada da sua aplicação decidindo para onde o tráfego vai.
Apache vs. Nginx: O Choque de Gerações
Eles são escolhas de ferramentas concorrentes, mas de gerações diferentes:
Apache: Criado nos anos 90, é o "tiozão" da internet. Super flexível, robusto e amigável, brilhou muito na era de ouro do PHP e do WordPress. O grande problema dele é a arquitetura: para cada pessoa que acessa o seu site, o Apache cria um processo novo na memória do servidor. Se entram mil pessoas de uma vez, ele cria mil processos e a sua memória RAM vai pro espaço.
Nginx (Lê-se "Engine-X"): É o padrão moderno e de alta performance, criado justamente para resolver esse vazamento de memória do Apache. Ele trabalha de forma assíncrona e orientada a eventos. Um único processo do Nginx consegue lidar com milhares de conexões simultâneas usando quase nada de RAM. É por isso que, para stacks modernas (Python, Go, Node), o Nginx é praticamente um monopólio.
Nuvem, IaaS e a Sopa de Letrinhas
Para quem estuda System Design (e não Design System — minha cabeça de ex-desenvolvedor front-end ainda dá uns bugs com isso de vez em quando!), o Nginx brilha quando falamos de Load Balance (Balanceamento de Carga) e DevOps.
O ponto é que muita gente hoje em dia programa há anos e nunca precisou encostar num Nginx. Por quê? Porque o mercado abstraiu muito a infraestrutura. Nós temos basicamente três grandes camadas de serviço:
SaaS (Software as a Service): O mais "family friendly", pronto para o usuário final.
PaaS (Platform as a Service): Onde a maioria dos devs mora. Vercel, Render, Heroku... Você joga o código lá e eles resolvem a infraestrutura mágica por trás.
IaaS (Infrastructure as a Service): Aqui a brincadeira fica séria. Você aluga a infraestrutura crua e o "DevOps" é você.
Para usar o Nginx de verdade, a gente precisa descer pro IaaS. Precisamos de uma VPS (Virtual Private Server), que é só um nome chique para "computador alugado" (aliás, quem foi o gênio que inventou de chamar o computador dos outros de "Nuvem"?). Você vai na AWS, Azure ou naquela alemã famosa, a Hetzner, e aluga uma máquina.
Nota mental sobre o mercado: antigamente se falava muito do GCP (Google Cloud Platform), mas hoje em dia as vagas parecem massivamente divididas entre AWS e Azure. Para os meus laboratórios, devo focar em Azure ou fazer tudo local mesmo usando Docker.
A Anatomia de uma Requisição: Servers, Proxies e App Servers
Vamos imaginar que a minha aplicação cresceu. Eu não posso ter um único contêiner rodando meu site, senão ele cai. Eu preciso de clones. Imagina que eu tenho réplicas rodando a minha API. Como o usuário acessa isso? É aqui que a arquitetura se divide em vários papéis. Dá uma olhada nesse fluxograma que preparei para ilustrar exatamente o ciclo de vida dessa requisição:
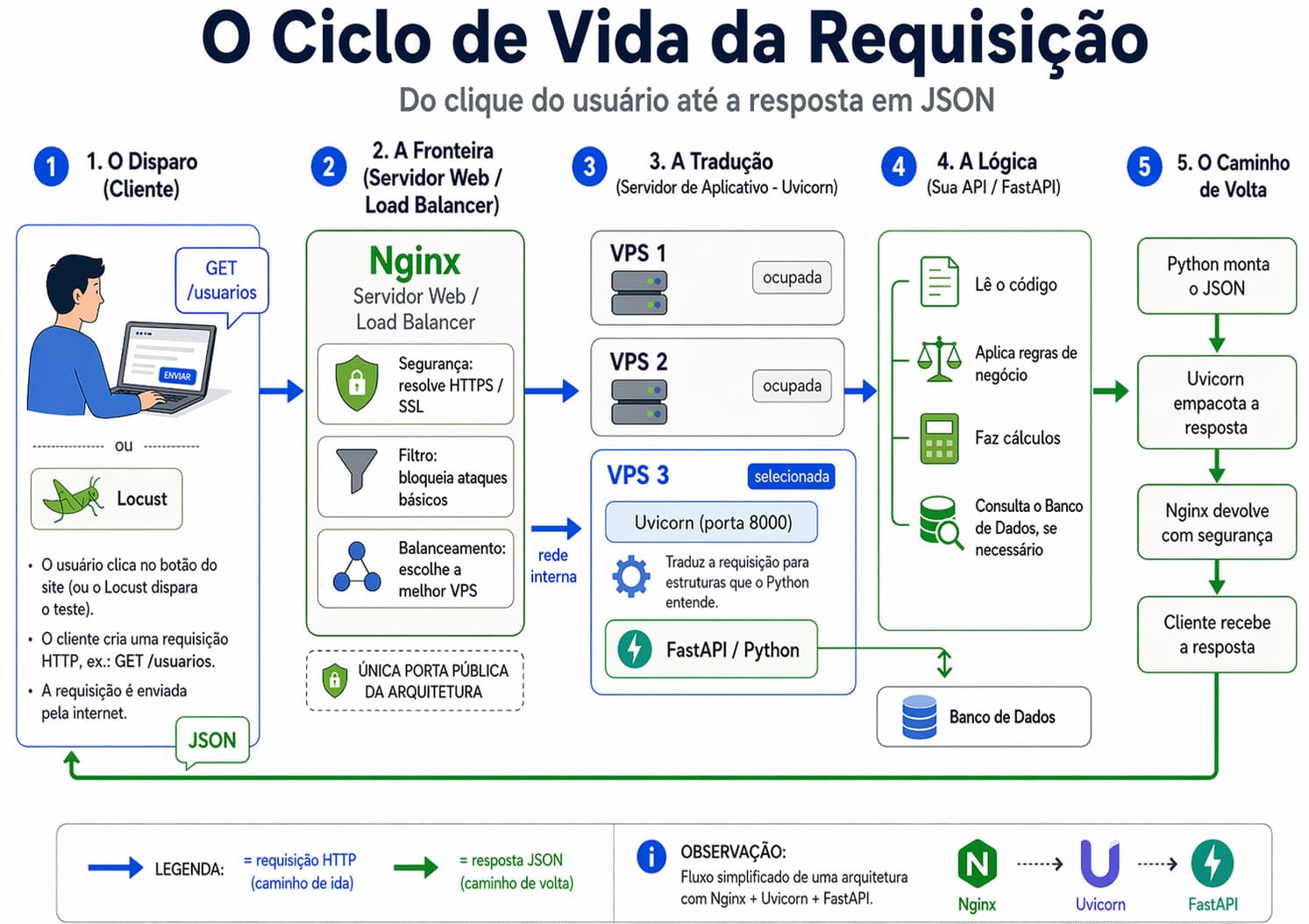
O Server Físico (A VPS): O computador real que alugamos.
O Web Server (Nginx): Fica em um contêiner isolado, bem na frente, recebendo a pancada da internet. Ele não entende código Python, não sabe o que é uma variável e não lê banco de dados. Ele só recebe pacotes e entrega pacotes. Nele, configuramos o Reverse Proxy e o Load Balance.
O App Server (Uvicorn, no caso do Python): Fica dentro de cada um dos contêineres da nossa API. Ele é o tradutor. Ele recebe a requisição limpa que veio do Nginx e diz: "Python, executa essa função aqui e me dá a resposta".
O Nginx fica na linha de frente distribuindo as cartas. E o mais legal: essa arquitetura simples de colocar o Nginx na frente já é a primeira grande linha de defesa contra os famosos ataques DDoS (Negação de Serviço).
Quando eu realmente preciso usar o Nginx? (A Escala de 1 a 5)
Muita gente acha que Load Balance e Nginx são coisas só pra Netflix. Mas a internet tem "níveis de poder" bem definidos:
Categoria 1 — O Projeto Fantasma (Hobby/Portfólio): De 0 a 1.000 acessos por mês. Uma maquininha minúscula (ou Vercel/Render). Tudo roda na mesma caixa (Web Server, App, Banco de dados). Custo: $0 a $10/mês.
Categoria 2 — A Padaria de Bairro (SaaS Iniciante): O negócio validou e dá dinheiro. Mil a 50 mil acessos por dia. Duas a quatro máquinas. O banco de dados já sai do servidor principal. O Nginx já aparece aqui na frente dividindo a carga entre dois ou três servidores da aplicação. Custo: $50 a $300/mês.
Categoria 3 — Startup em Tração (App Nacional): Picos cruéis de acesso (ex: Ifood na hora do almoço). Milhões de requisições por dia. O servidor fixo morre e entra o Auto Scaling (a nuvem liga e desliga máquinas sozinha). Começamos a usar Filas (RabbitMQ/SQS), Cache em memória (Redis) e o Load Balance passa a ser gerenciado pela própria nuvem (AWS ALB). Custo: $2k a $15k/mês.
Categoria 4 — O Unicórnio (Gigantes como Nubank/Uber): O sistema não pode cair, senão sai no G1. Bilhões de requisições. Entra a arquitetura de Microsserviços (o login roda em 50 servidores, o pagamento em outros 50). Bancos relacionais começam a não dar conta, entram os NoSQL (DynamoDB, Cassandra) e mensageria pesada (Kafka). Custo: $100k a $1M/mês.
Categoria 5 — Os Titãs (Google, Meta, Netflix): Fronteira da física. O problema não é software, é a velocidade da luz nos cabos submarinos. Eles não usam quase nada de prateleira. Têm servidores dentro da sua operadora local (Edge Computing) e sincronizam bancos de dados com relógios atômicos. Custo: Centenas de milhões.
O Laboratório Prático (Mão na Massa)
Para não tomar um bloqueio de cartão de crédito testando carga na nuvem, montei o laboratório 100% local com Docker Compose. A arquitetura ficou assim:
3 Contêineres de réplica da minha API (FastAPI + Uvicorn). 1 Contêiner Nginx na frente atuando como Proxy Reverso e Load Balancer. Prometheus + Grafana para monitoramento. Locust para teste de estresse (mandar pancada de requisições).
Monitoramento: O Segredo do cAdvisor
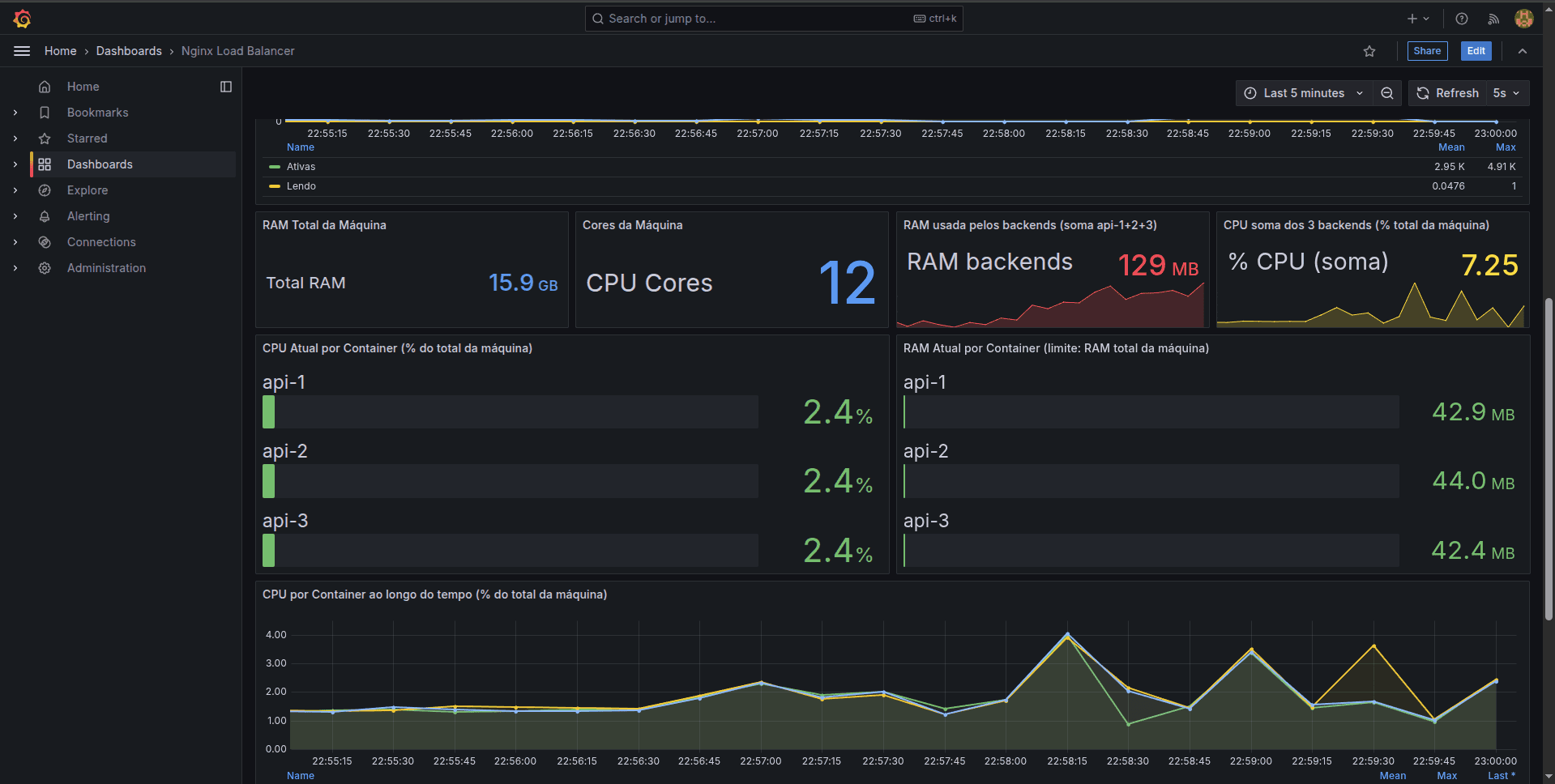
O Grafana por padrão não mostra quanto de RAM e CPU seus contêineres estão gastando. Para isso, precisamos de uma ferramenta do Google chamada cAdvisor (Container Advisor). Ele é um agente, escrito em Go, que fica espionando a temperatura (CPU/RAM) de todos os contêineres e formata isso pro Prometheus ler.
Descobri que contêineres não têm limite próprio por padrão; o limite deles é o gargalo da sua máquina física. Dá uma olhada no painel que eu montei. Nele dá pra ver que a minha API de teste tem um consumo baixíssimo (uns 40MB de RAM por contêiner), mesmo consumindo parte dos 12 núcleos da máquina. Ter essa visão no Grafana é sensacional:
Estressando com o Locust (O conceito de Ramp Up)
O Locust tem duas configurações principais: o número total de usuários (o limite da carga) e o Ramp Up. O Ramp Up é a taxa de subida: quantos usuários entram por segundo. Quanto maior o Ramp Up, mais brusca é a pancada, porque a carga total é atingida muito rápido.
Para os testes, configurei uma carga bacana com uma subida controlada:
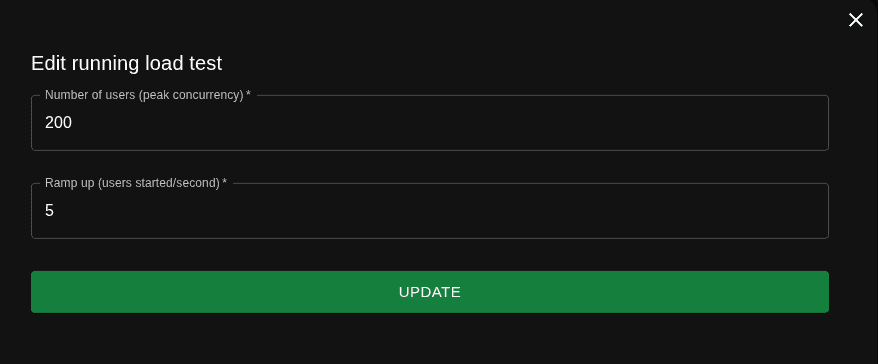
Escolher um Ramp Up menor (subir de forma gradual) é ótimo para criar uma linha de estresse longa, dando tempo para você ver no Grafana o segundo exato em que o servidor começa a "pedir água" e gargalar.
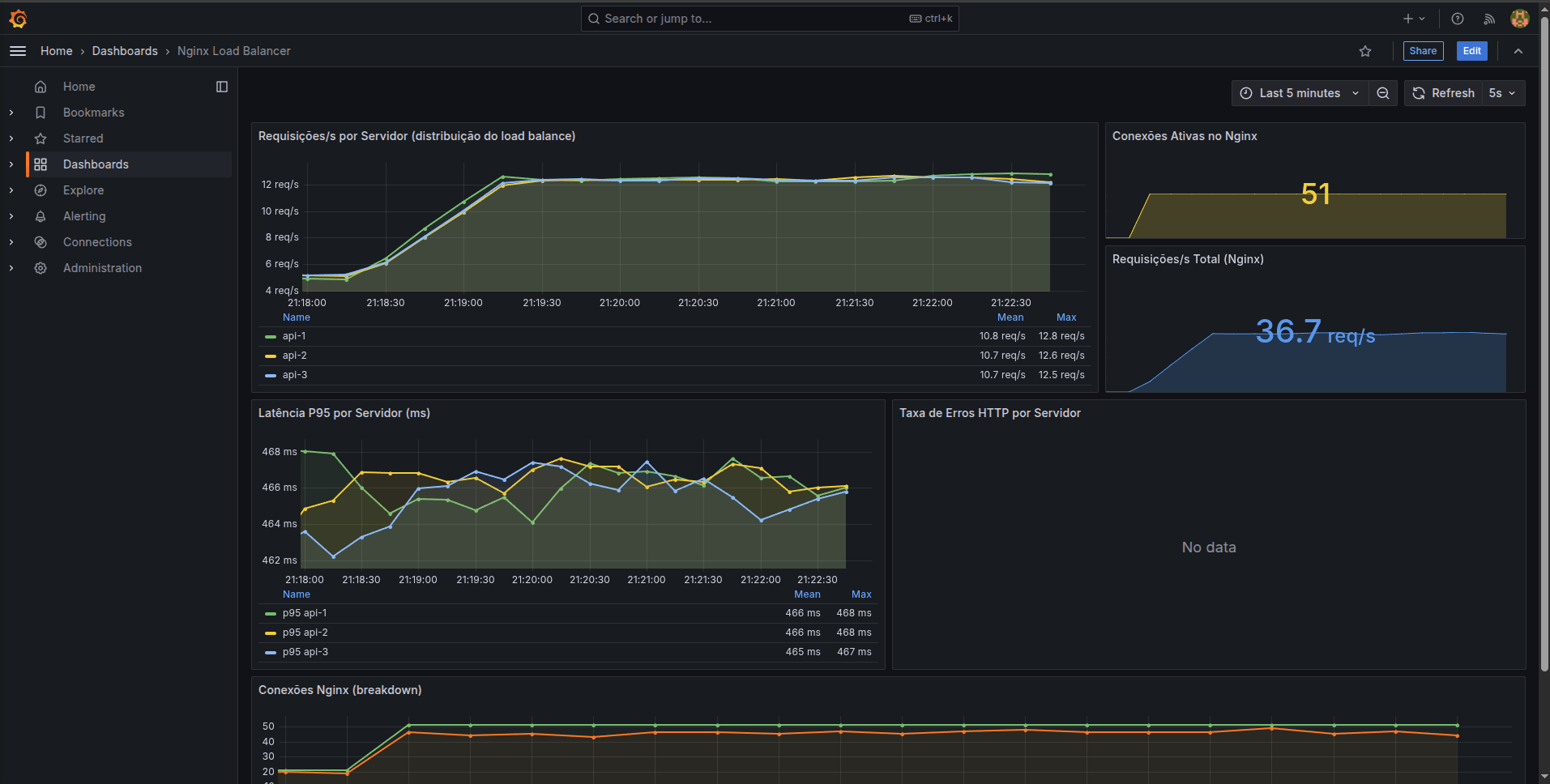
A Mágica da Latência P95
No Grafana, a métrica de ouro não é a "Latência Média", é o P95 (Percentil 95). Ele mostra o tempo de resposta que 95% dos usuários tiveram. A gente usa isso porque a Média é mentirosa: se 99 clientes carregam o site em 10ms, mas 1 cliente perde o sinal do 3G no túnel e demora 5 segundos, a média joga o tempo de todo mundo lá pra cima. O P95 corta os 5% de "outliers azarados" e te mostra a realidade do seu servidor de forma limpa. Empresas insanas por performance usam o P99.
Nesse meu dashboard focado no Load Balancer, as requisições estão perfeitamente divididas entre as 3 APIs, e a latência P95 se mantém super saudável:
E o Kubernetes?
O K8s é state-of-the-art para empresas da Categoria 3 pra cima. Em vez de você configurar servidor por servidor, o K8s é o "cérebro" que gerencia centenas de VPSs agrupadas e faz a auto-cura (se a máquina pegar fogo, ele sobe o contêiner em outra). É complexo e pesado (gasta uns 2GB de RAM só para existir). Para projetos pequenos e médios, o Docker Compose dá conta com maestria.
Dissecando o nginx.conf
Para provar que o Nginx não é um bicho de sete cabeças, olha como a configuração real do Load Balance e do Proxy Reverso fica enxuta no código:
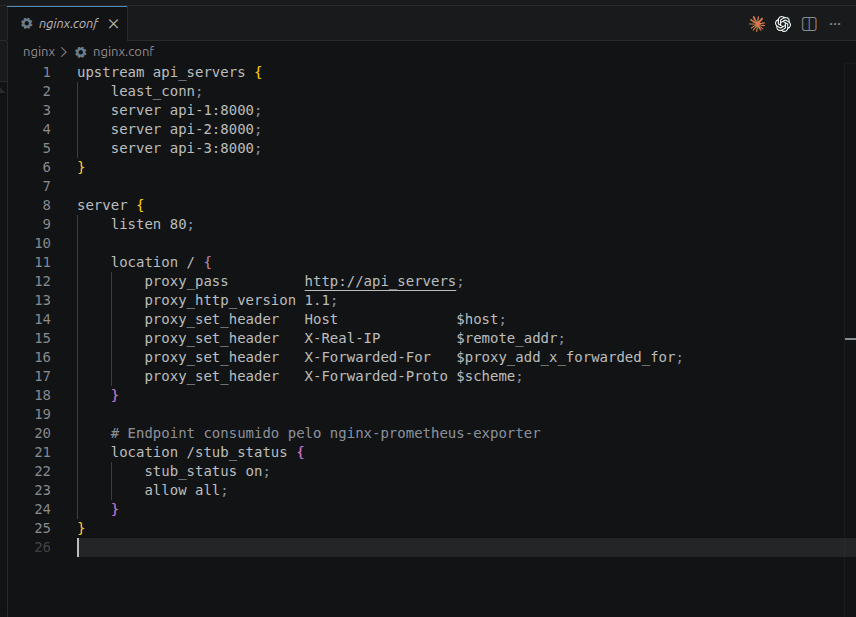
Aqui está a tradução visual exata do que esse bloco de código está fazendo:
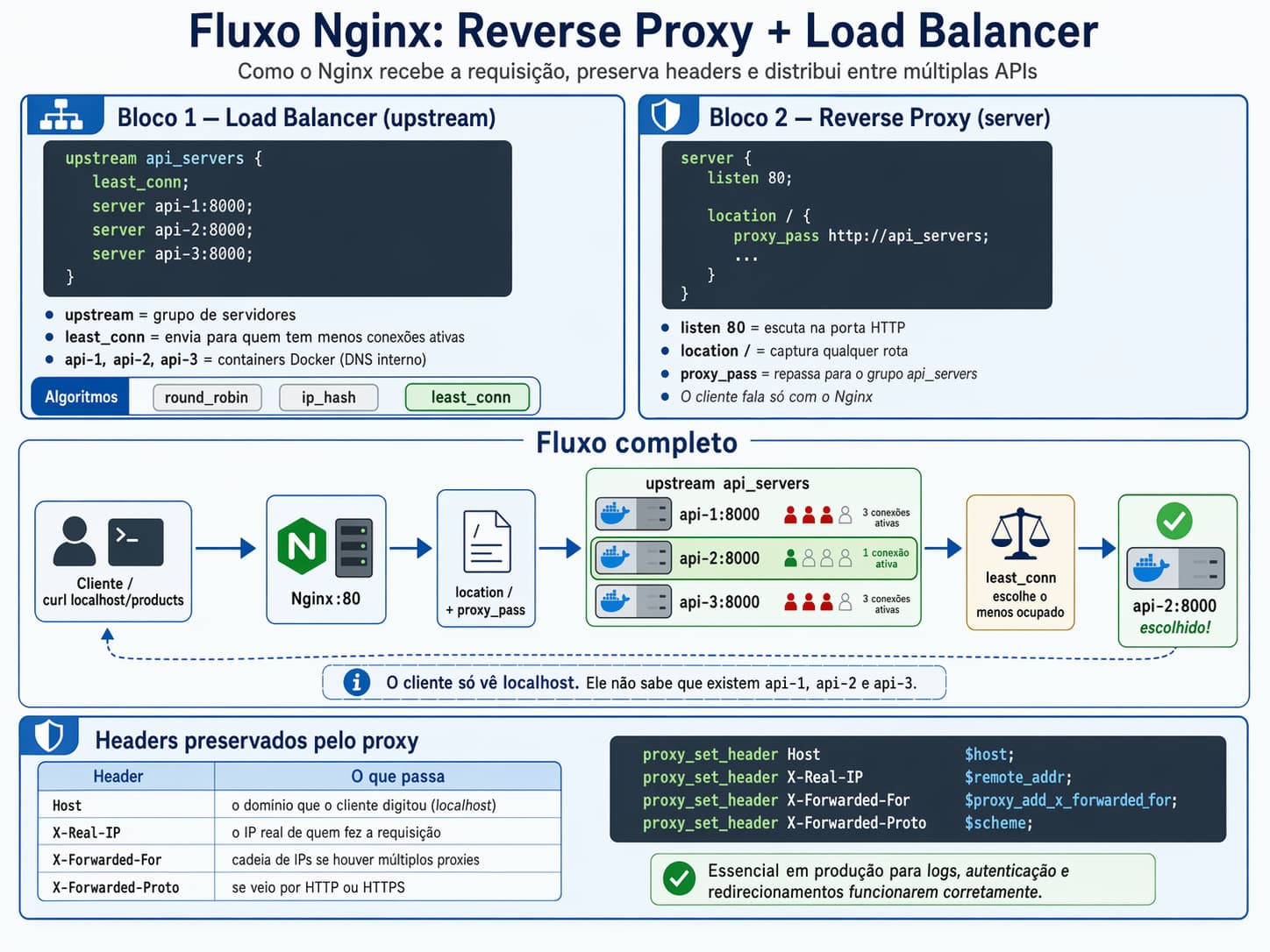
O upstream cria um grupo com as nossas APIs. O least_conn é o algoritmo de distribuição inteligente: ele joga a próxima requisição para a API que estiver mais desocupada — melhor que o round_robin que só distribui em círculo, ou o ip_hash que prende o usuário na mesma máquina. Os nomes api-1, etc., são resolvidos pelo próprio DNS interno do Docker.
O bloco server é o Web Server em si, escutando a porta 80. O proxy_pass é a mágica: ele pega o que chegou e joga para o nosso grupo de APIs lá em cima. O cliente só vê o Nginx e nem sonha que existem 3 APIs por trás.
Essas linhas de proxy_set_header são vitais. Se a gente não passar isso, a API vai achar que quem fez a requisição foi o IP do próprio Nginx. Esses headers garantem que o IP real do cliente chegue lá no back-end para gerar logs e autenticações corretas.
Conclusão: Nginx é Web Server ou Proxy Reverso?
Uma dúvida comum: "Se o Proxy Reverso já é o Web Server mais seguro, eu só uso ele, certo?" Depende! O Nginx é Fullstack. Ele pode atuar de três formas na mesma máquina:
Só Web Server: Para um blog HTML/CSS estático. Usa-se a diretiva root /pasta no location. Ele entrega arquivos do HD na velocidade da luz.
Só Proxy Reverso: O nosso laboratório acima. O Nginx atua só como o escudo/roteador repassando tráfego pro Python processar.
Híbrido (O cenário real Fullstack): No mesmo nginx.conf, você pode ter um location / servindo os arquivos estáticos do seu front-end em React, e um location /api/ fazendo o proxy_pass pro seu back-end em FastAPI.
No fim do dia, ver aquele gráfico de requisições do Grafana dividindo perfeitamente as linhas de tráfego entre os meus três contêineres foi como ver as engrenagens de uma máquina colossal rodando em sincronia perfeita. Aprender a orquestrar tudo isso não é apenas escrever linhas de código, é entender como a nossa aplicação ganha vida, resiste ao caos e escala para enfrentar o mundo real. É desbravar um território novo onde você deixa de ser só o construtor da peça e passa a ser o arquiteto do ecossistema inteiro.
E que venham os próximos desafios! RabbitMQ e Kafka já estão na mira.